AD


Oct. 27 2023
眼見不一定為憑?生成式 AI 帶來的信任危機!
-
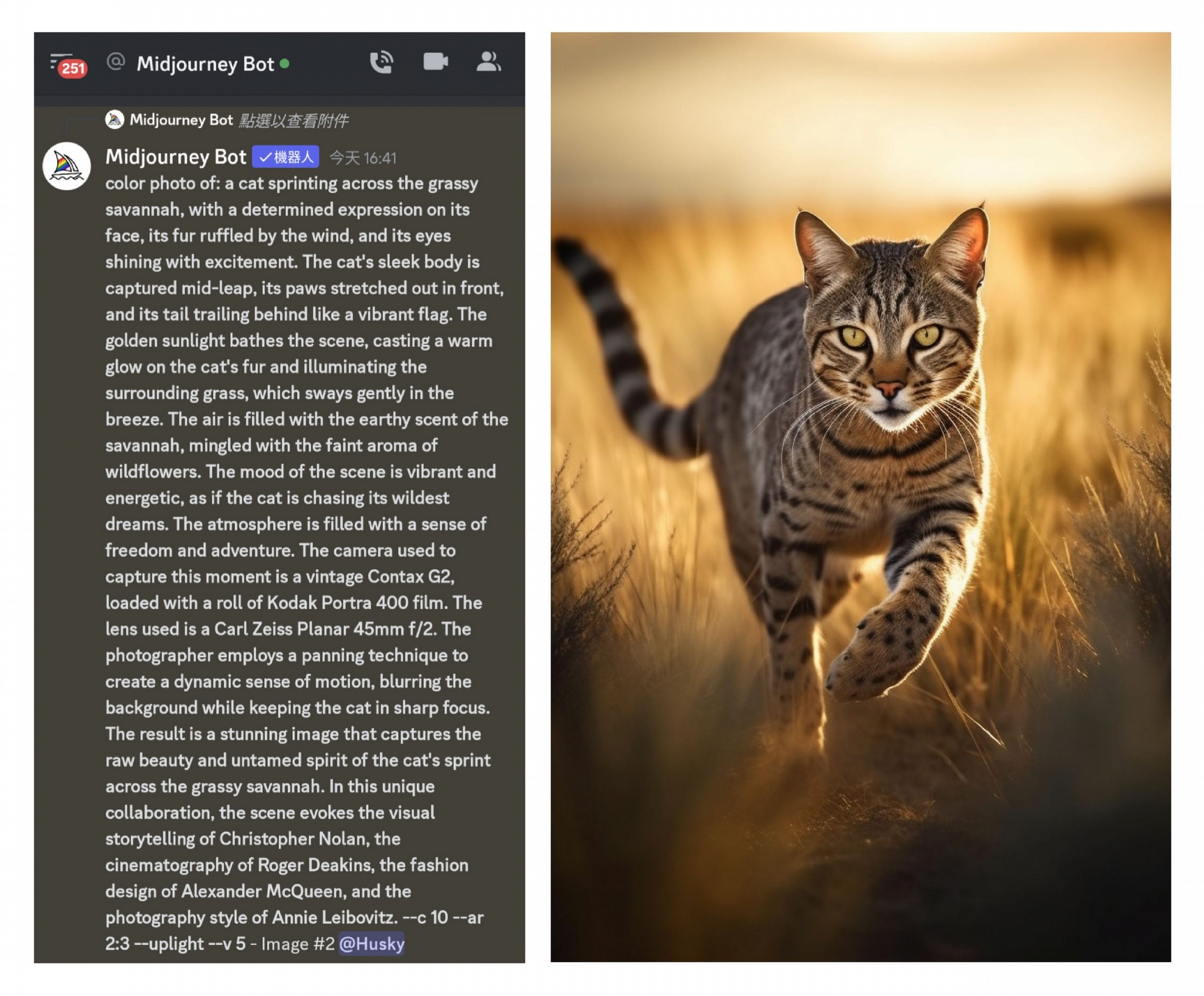
提示詞給的資訊越多,就越有機會用繪圖 AI 生成想要的客製化圖片。 圖|研之有物(資料來源|Midjourney)
-
提示詞給的資訊越多,就越有機會用繪圖 AI 生成想要的客製化圖片。 圖|研之有物(資料來源|Midjourney)
-
提示詞給的資訊越多,就越有機會用繪圖 AI 生成想要的客製化圖片。 圖|研之有物(資料來源|Midjourney)
-
提示詞給的資訊越多,就越有機會用繪圖 AI 生成想要的客製化圖片。 圖|研之有物(資料來源|Midjourney)
-
提示詞給的資訊越多,就越有機會用繪圖 AI 生成想要的客製化圖片。 圖|研之有物(資料來源|Midjourney)
| 訪客 | 一般會員 | 全閱讀會員 | |
| 費用 | 完全免費 | 完全免費 | 依方案價格 |
| 暢讀精選文章 | |||
| 活動優先報名 | |||
| 精選書籍折扣 | |||
| 去除廣告干擾 | |||
| 暢讀付費內容 |
AD



AD
熱門精選




AD
相關推薦





AD